I am passionate about creating data infrastructure that supports the long term needs of a project or organization, so the team has trustworthy data needed to inform decisions. In my work this has included designing and managing data stored in MySQL and Microsoft SQL Server databases, a Redshift data warehouse, and S3 file data storage.
A large portion of the work in developing a useful database is getting the needed data in and out effectively. I have experience developing automated data pipelines using SQL, Python, R, Scala, Spark, AWS Lambda, and AWS EC2. I regularly utilize Git repositories to support collaboration, peer review, and version control.
See below for a few examples of related projects I have worked on.
In my work at Remitly I created data pipelines to provide data needed for decision making. When a new data source was identified as having high potential to inform marketing decisions, I created a new data pipeline to address this need, including:
- I worked with stakeholders, including marketers and data analysts, to understand the data they needed to make relevant decisions and data sources they were currently using for this purpose.
- I used this information to design a data table that would be useful for analytics and decision making.
- I collaborated with a data vendor to provide the desired data, which was set up to be delivered daily to files in an AWS S3 bucket.
- I wrote Python, Scala, and Spark scripts to process these data files. For all recent data files with relevant data updates, the scripts extract the data to an internal storage bucket, convert it to the desired format, and perform automated unit testing. All historical transformed data are combined and uploaded to an AWS Redshift data warehouse.
- I compared these data with other data sources and resolved issues (e.g. periods of missing data) and documented the data including providing column definition summaries.
- I shared the data and documentation with stakeholders so data from this new table could be incorporated into dashboards used for regular decision making.
At Four Peaks Environmental Science & Data Solutions, I worked on several projects using acoustic telemetry to track the movement of juvenile Pacific salmon near hydroelectric dams in Washington and Oregon. Raw data files, up to 20GB, of acoustic detections from up to 25 acoustic receivers needed to be quickly analyzed on a weekly basis to provide timely and reliable insights to natural resource managers. I worked with two other colleagues to design and implement a data pipeline to process and provide insights from these data files. In this data pipeline raw data files would be uploaded by colleagues to AWS S3, which would initiate several steps of AWS Lambda processes running Python scripts to process the data, saving intermediate and final versions of the processed data to S3. These scripts also generated PDF files with data visualizations to allow for quick monitoring of the data quality and interpretation of findings to communicate to stakeholders. We also implemented alerts in AWS CloudWatch to inform us of any data anomalies or quality issues, so we could address issues in a timely manner.

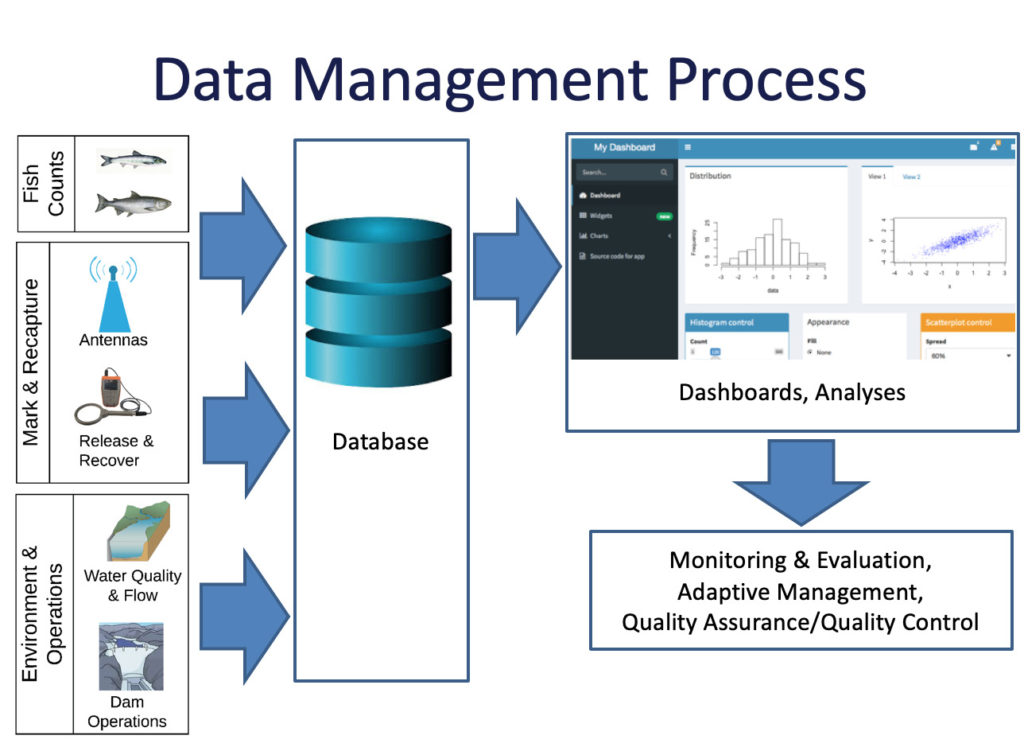
Hydroelectric dams can have large impacts on natural resources in their vicinity, including juvenile Pacific salmon moving downstream, which can be best understood and addressed with relevant data. Through my work at Four Peaks Environmental Science & Data Solutions, I designed, implemented, and supported data systems to provide reliable and useful data to help natural resource managers understand factors impacting the movement and survival of juvenile salmon. This included developing automated systems to extract data on fish counts uploaded through a custom data form, fish tagging and detection data extracted from a centralized regional database (PTAGIS), and environmental variables recorded by several different logging devices into a SQL database. I developed and maintained dashboards in Shiny (R) and Django (Python) to provide easy access and visualization to the data in these databases, to support regular use for decision making.
I shared related insights through a presentation at the 2019 Washington-British Columbia American Fisheries Society Chapter Annual Meeting.
To enable more efficient analyses of customer journeys through the Remitly app and website and calculation of related key metrics, I wrote SQL and Scala scripts to provide summarized data within tables in an AWS Redshift data warehouse. I took the time to understand existing data tables and metrics, identified opportunities for metrics summaries to better needs for regular decision making, evaluated existing queries with long runtimes to run to identify opportunities to query optimization, iterated based on feedback from colleagues, and documented and communicated the new and updated data tables.